Поддержка процесса от разведочного анализа до отображения данных
Deductor Studio позволяет пройти все этапы анализа данных. Схема на рис. 26.2 отображает процесс извлечения знаний из данных.
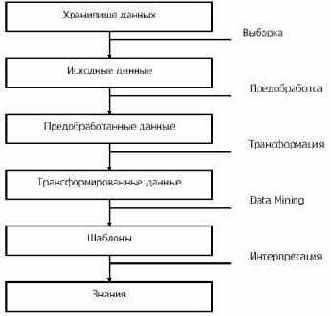
Рис. 26.2. Процесс извлечения знаний из данных в Deductor Studio
Рассмотрим этот процесс более детально.
На начальном этапе в программу загружаются или импортируются данные из какого-либо произвольного источника. Хранилище данных Deductor Warehouse является одним из источников данных. Поддерживаются также другие, сторонние источники:
- текстовый файл с разделителями;
- Microsoft Excel;
- Microsoft Access;
- Dbase;
- CSV-файлы;
- ADO-источники - позволяют получить информацию из любого ODBC-источника (Oracle, MS SQL, Sybase и прочее).
Обычно в программу загружаются не все данные, а какая-то выборка, необходимая для дальнейшего анализа.
После получения выборки можно получить подробную статистику по ней, посмотреть, как выглядят данные на диаграммах и гистограммах.
После такого разведочного анализа можно принимать решения о необходимости предобработки данных. Например, если статистика показывает, что в выборке есть пустые значения (пропуски данных), можно применить фильтрацию для их устранения.
Предобработанные данные далее подвергаются трансформации. Например, нечисловые данные преобразуются в числовые, что необходимо для некоторых алгоритмов. Непрерывные данные могут быть разбиты на интервалы, то есть производится их дискретизация.
К трансформированным данным применяются методы более глубокого анализа. На этом этапе выявляются скрытые зависимости и закономерности в данных, на основании которых строятся различные модели. Модель представляет собой шаблон, который содержит формализованные знания.
Последний этап - интерпретация - предназначен, чтобы из формализованных знаний получить знания на языке предметной области.