Архитектура Deductor Studio
Вся работа по анализу данных в Deductor Studio базируется на выполнении следующих действий:
- импорт данных;
- обработка данных;
- визуализация;
- экспорт данных.
На рис. 26.3 показана схема функционирования Deductor Studio. Отправной точкой для анализа всегда является процедура импорта данных. Полученный набор данных может быть обработан любым из доступных способов.
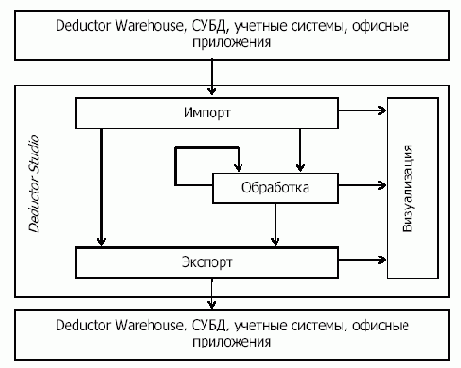
Рис. 26.3. Схема функционирования Deductor Studio
Результатом обработки также является набор данных, который, в свою очередь, опять может быть обработан. Импортированный набор данных, а также данные, полученные на каждом этапе обработки, могут быть экспортированы для последующего использования в других, например, в учетных системах. Поддерживаются следующие форматы:
- хранилище данных Deductor Warehouse ;
- Microsoft Excel;
- Microsoft Word;
- HTML;
- XML;
- Dbase;
- буфер обмена Windows;
- текстовой файл с разделителями.
Результаты каждого действия можно отобразить различными способами:
- OLAP-кубы (кросс-таблица, кросс-диаграмма);
- плоская таблица;
- диаграмма, гистограмма;
- статистика;
- анализ по принципу "что-если";
- граф нейросети;
- дерево - иерархическая система правил;
- прочее.
Способ возможных отображений зависит от выбранного метода обработки данных. Например, нейросеть содержит визуализатор "Граф нейросети", специфичный только для нее. Некоторые способы визуализации пригодны почти для всех методов обработки, например, в виде таблицы, диаграммы или гистограммы.
Последовательность действий, которые необходимо провести для анализа данных, называется сценарием.
Сценарий можно автоматически выполнять на любых данных. Типовой сценарий изображен на рис. 26.4.
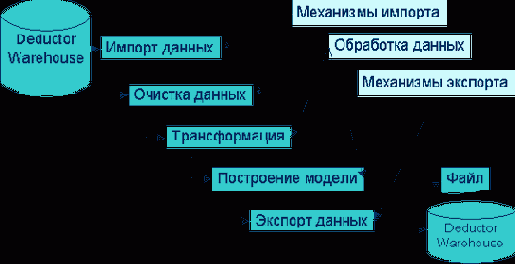
Рис. 26.4. Типовой сценарий Deductor Studio