SEMMA методология
SEMMA методология реализована в среде SAS Data Mining Solution (SAS) [102]. Ее аббревиатура образована от слов Sample ("Отбор данных", т.е. создание выборки), Explore ("Исследование отношений в данных"), Modify ("Модификация данных"), Model ("Моделирование взаимозависимостей"), Assess ("Оценка полученных моделей и результатов"). Методология разработки проекта Data Mining в соответствии с методологией SEMMA изображена на рис. 21.3.
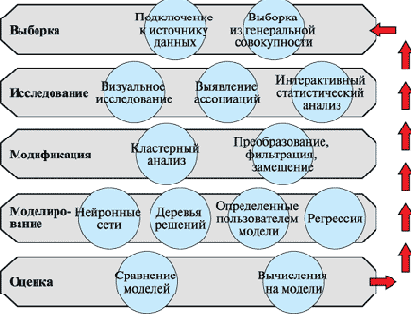
Рис. 21.3. Методология разработки проекта Data Mining в соответствии с методологией SEMMA
Подход SEMMA подразумевает, что все процессы выполняются в рамках гибкой оболочки, поддерживающей выполнение всех необходимых работ по обработке и анализу данных. Подход SEMMA сочетает структурированность процесса и логическую организацию инструментальных средств, поддерживающих выполнение каждого из шагов. Благодаря диаграммам процессов обработки данных, подход SEMMA упрощает применение методов статистического исследования и визуализации, позволяет выбирать и преобразовывать наиболее значимые переменные, создавать модели с этими переменными, чтобы предсказать результаты, подтвердить точность модели и подготовить модель к развертыванию.
Эта методология не навязывает каких-либо жестких правил. В результате использования методологии SEMMA разработчик может располагать научными методами построения концепции проекта, его реализации, а также оценки результатов проектирования.
По результатам последних опросов KDnuggets (2004 г.), 42% опрошенных лиц использует методологию CRISP-DM, 10% - методологию SEMMA, 6% - собственную методологию организации, 28% - свою собственную методологию, другими методологиями пользуется 6% опрошенных. Не пользуются никакой методологией 7% опрошенных.